


18. Sora's Diffusion Transformer (DiT)
Can you calculate this by hand? ✍️

OpenAI’s Sora took over the Internet when it was announced earlier in 2024. The technology behind Sora is the Diffusion Transformer (DiT) developed by William Peebles and Shining Xie in 2023.
How does DiT work?
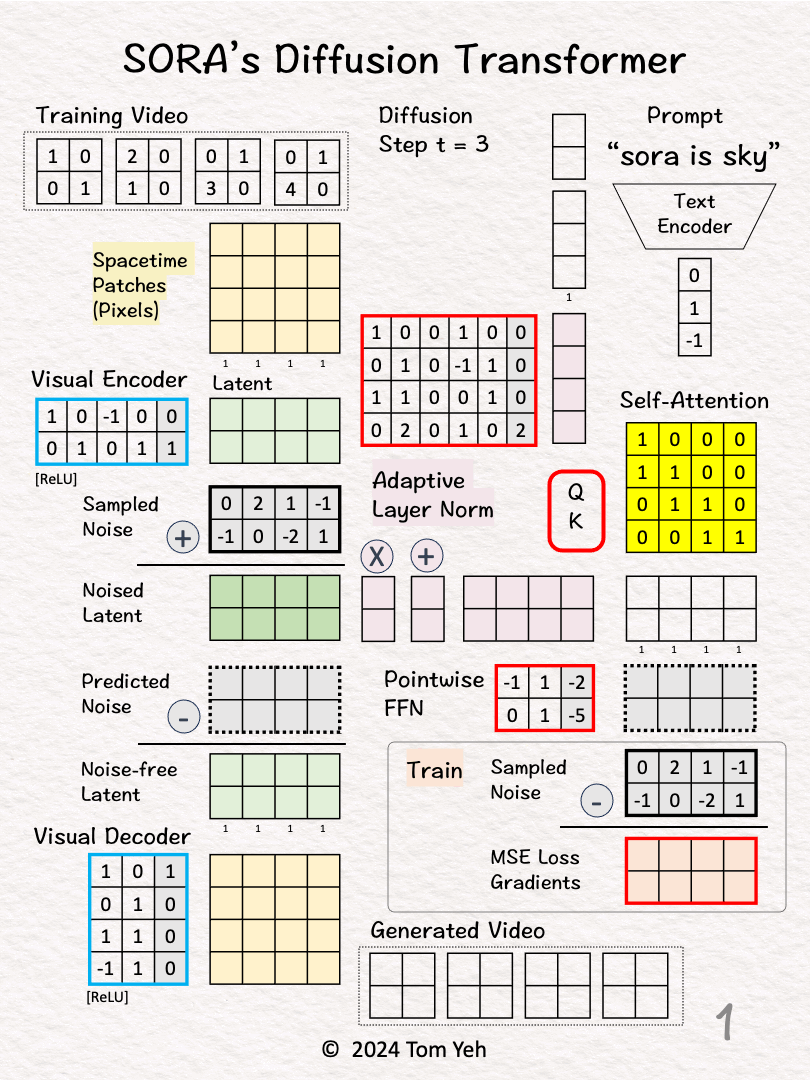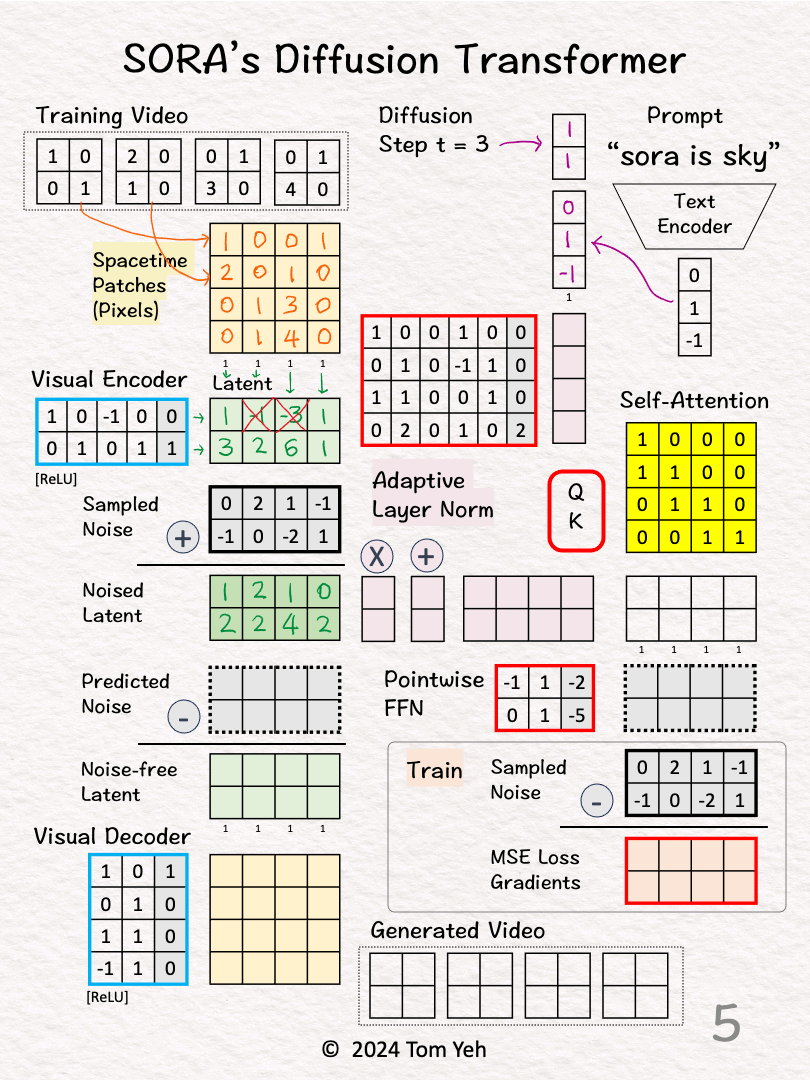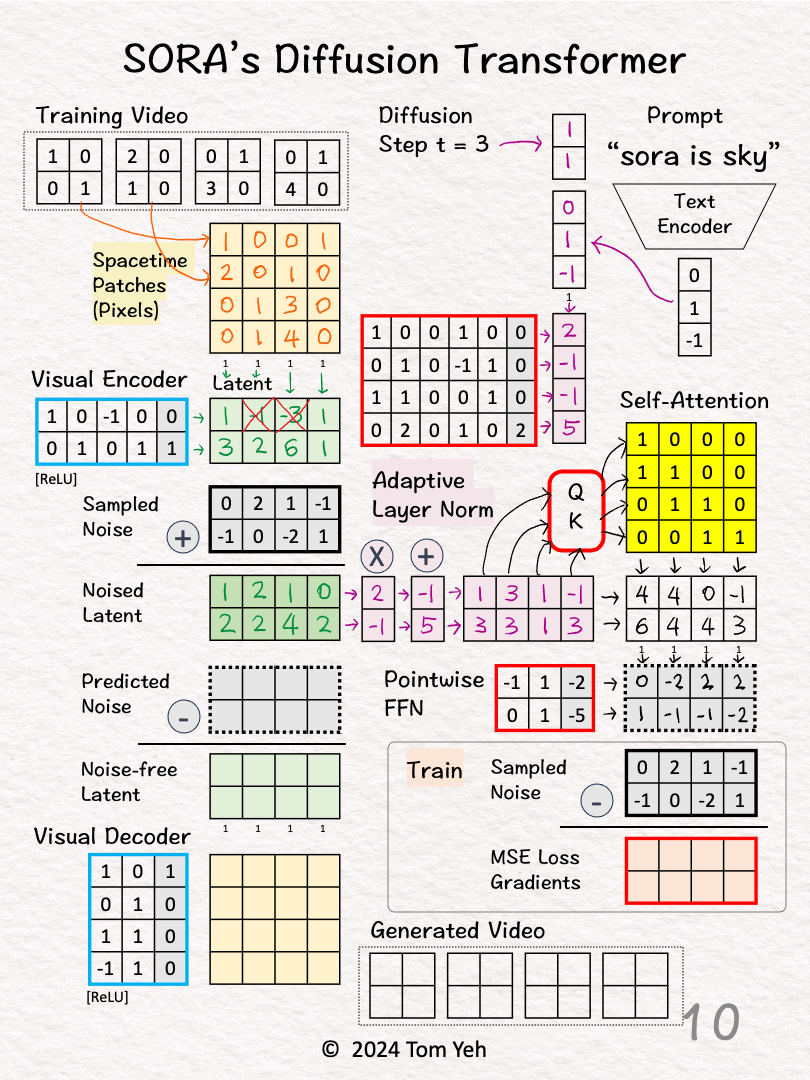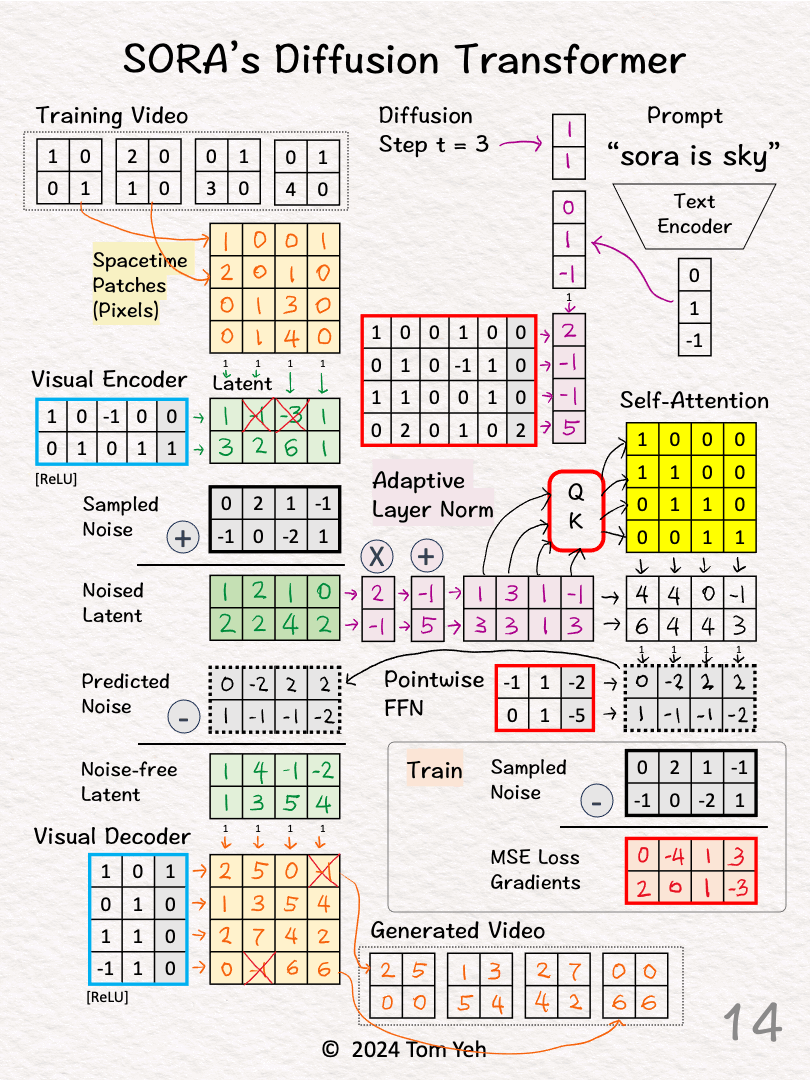
Walkthrough
Goal: Generate a video conditioned by a text prompt and a series of diffusion steps
[1] Given
↳ Video
↳ Prompt: "sora is sky"
↳ Diffusion step: t = 3
[2] Video → Patches
↳ Divide all pixels in all frames into 4 spacetime patches
[3] Visual Encoder: Pixels 🟨 → Latent 🟩
↳ Multiply the patches with weights and biases, followed by ReLU
↳ The result is a latent feature vector per patch
↳ The purpose is dimension reduction from 4 (2x2x1) to 2 (2x1).
↳ In the paper, the reduction is 196,608 (256x256x3)→ 4096 (32x32x4)
[4] ⬛ Add Noise
↳ Sample a noise according to the diffusion time step t. Typically, the larger the t, the smaller the noise.
↳ Add the Sampled Noise to latent features to obtain Noised Latent.
↳ The goal is to purposely add noise to a video and ask the model to guess what that noise is.
↳ This is analogous to training a language model by purposely deleting a word in a sentence and ask the model to guess what the deleted word was.
[5-7] 🟪 Conditioning by Adaptive Layer Norm
[5] Encode Conditions
↳ Encode "sora is sky" into a text embedding vector [0,1,-1].
↳ Encode t = 3 to as a binary vector [1,1].
↳ Concatenate the two vectors in to a 5D column vector.
[6] Estimate Scale/Shift
↳ Multiply the combined vector with weights and biases
↳ The goal is to estimate the scale [2,-1] and shift [-1,5].
↳ Copy the result to (X) and (+)
[7] Apply Scale/Sift
↳ Scale the noised latent by [2,-1]
↳ Shifted the scaled noised latent by [-1, 5]
↳ The result is "conditioned" noise latent.
[8-10] Transformer
[8] Self-Attention
↳ Feed the conditioned noised latent to Query-Key function to obtain a self-attention matrix
↳ Value is omitted for simplicity
[9] Attention Pooling
↳ Multiply the conditioned noised latent with the self-attention matrix
↳ The result are attention weighted features
[10] Pointwise Feed Forward Network
↳ Multiply the attention weighted features with weights and biases
↳ The result is the Predicted Noise
🏋️♂️ Train
[11]
↳ Calculate MSE loss gradients by taking the different between the Predicted Noise and the Sampled Noise (ground truth).
↳ Use the loss gradients to kick off backpropagation to update all learnable parameters (red borders)
↳ Note the visual encoder and decoder's parameters are frozen (blue borders)
🎨 Generate (Sample)
[12] Denoise
↳ Subtract the predicted noise from the noised latent to obtain the noise-free latent
[13] Visual Decoder: Latent 🟩 → Pixels 🟨
↳ Multiply the patches with weights and biases, followed by ReLU
[14] Patches → Video
↳ Rearrange patches into a sequence of video frames.