


20. Reinforcement Learning with Human Feedback (RLHF)
Can you calculate this by hand? ✍️

Reinforcement Learning from Human Feedback (RLHF) is a popular technique to ensure that an LLM aligns with ethical standards and reflects the nuances of human judgment and values.
Without RLHF, an LLM relies only on data and would think doctors must be men, because the data likely reflects existing biases in our society.
With RLHF, an LLM is given human feedback that doctors can be both man and women. The LLM can update its weights until it begins to use "them" rather than "him" to refer to a doctor.
Moreover, we hope the LLM not only addresses the specific bias about doctors but also learns the underlying value of "gender neutrality" and applies it to other professions, for example, learns to use "them" to refer to a CEO, even though it wasn't explicitly taught by a human.
Claude 3 released by Anthropic, sets a new high bar for safety standards. It uses an advanced technique called "Constitutional AI" by extending RLHF, enhancing the H in RLHF with AI.
How does RLHF work?
𝗪𝗮𝗹𝗸𝘁𝗵𝗿𝗼𝘂𝗴𝗵
[1] Given
↳ Reward Model (RM)
↳ Large Language Model (LLM)
↳ Two (Prompt, Next) Pairs
🟪 TRAIN RM
Goal: Learn to give higher rewards to winners
[2] Preferences
↳ A human reviews the two pairs and picks a "winner"
↳ (doc is, him) < (doc is, them) because the former has gender bias.
[3]-[6] Calculate the Reward for Pair 1 (Loser)
[3] Word Embeddings
↳ Lookup word embeddings as inputs to the RM
[4] Linear Layer
↳ Multiply the input vectors with RM's weights and biases (4x4 matrix)
↳ Output: feature vectors
[5] Mean Pool
↳ Multiply the features with the column vector [1/3,1/3,1/3] that achieves the effect of averaging the features across the three positions
↳ Output: sentence embedding vector
[6] Output Layer
↳ Multiply the sentence embedding with the weights and biases (1x5 matrix)
↳ Output: Reward = 3
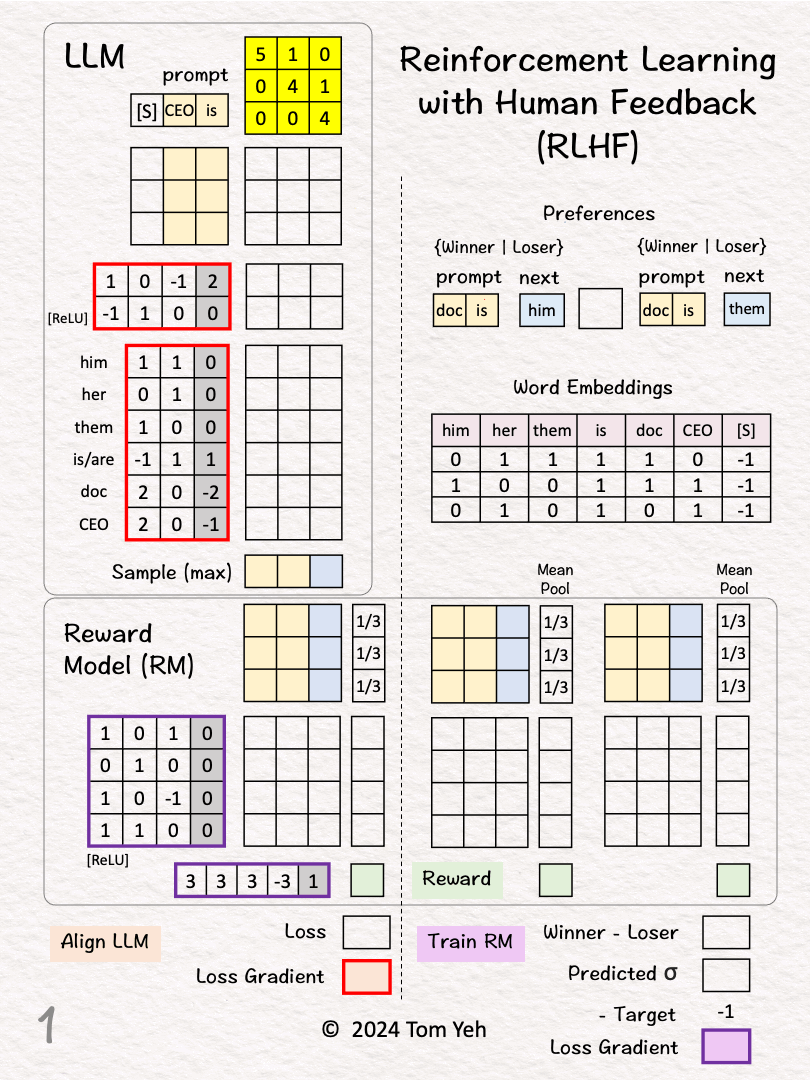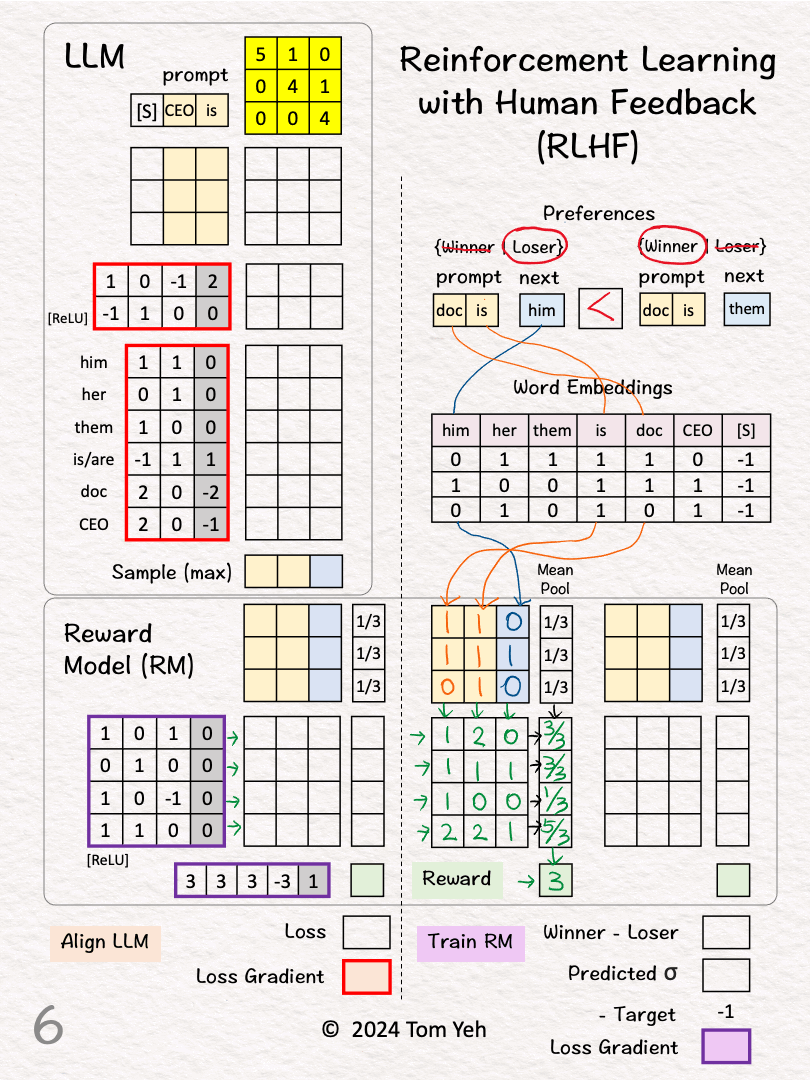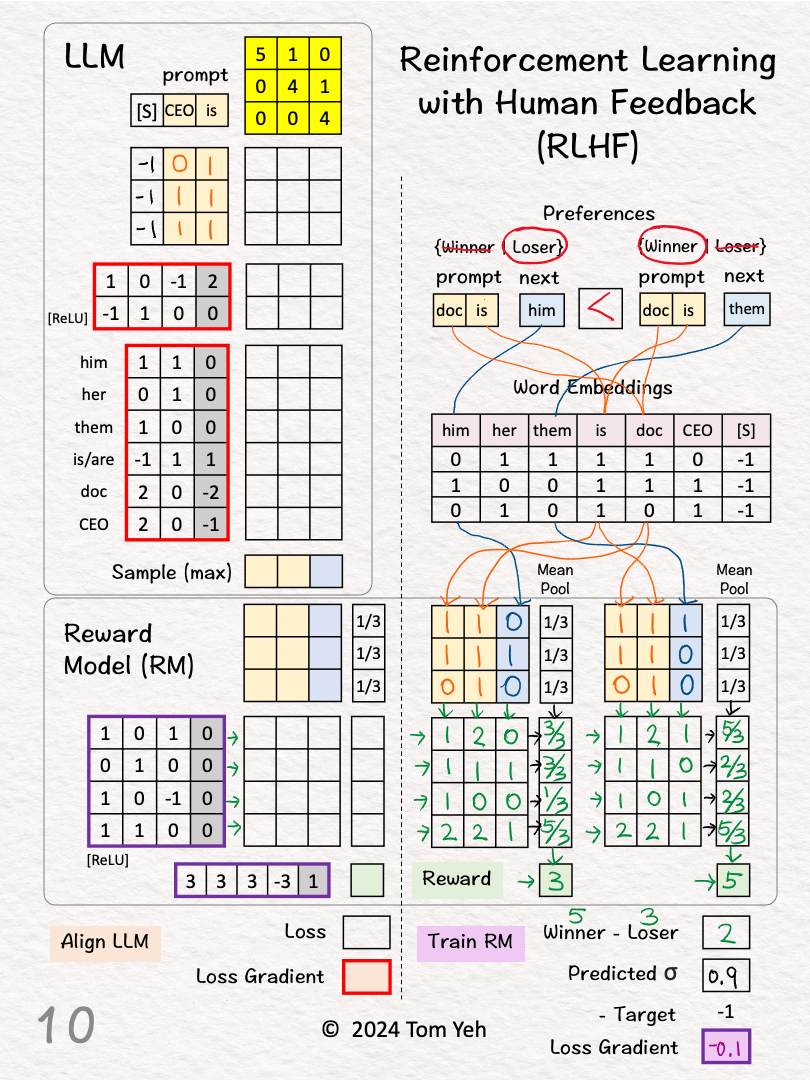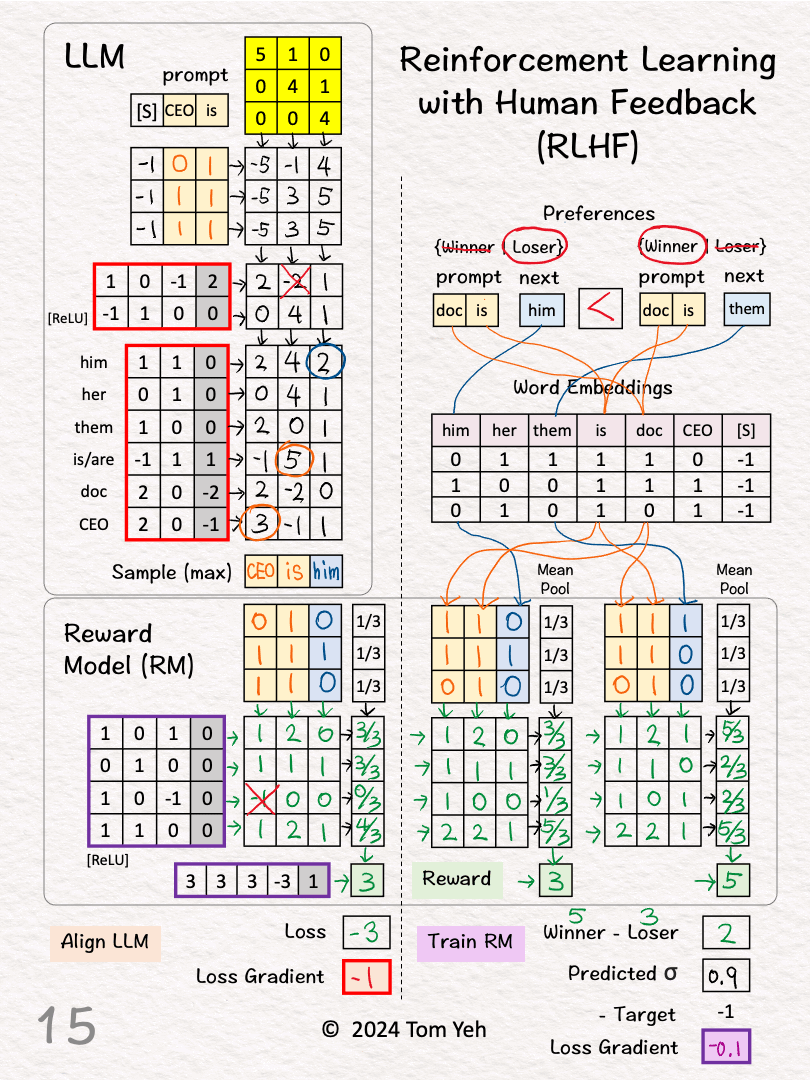
[7] Reward for Pair 2 (Winner)
↳ Repeat [3]-[6]
↳ Output: Reward = 5
[8] Winner vs Loser's Reward
↳ Calculate the difference between the winner and the loser's reward
↳ RM wants this gap to be positive and as large as possible
↳ 5 - 3 = 2
[9] Loss Gradient
↳ Map reward gap to a probability value as prediction: σ(2) ≈ 0.9
↳ Calculate loss gradient by Prediction - Target: 0.9 - 1 = -0.1
↳ The Target is 1 because we want to maximize the reward gap.
↳ Run backpropagation and gradient descent to update RM's weights and biases (purple border)
🟧 ALIGN LLM
Goal: Update weights to maximize rewards
[10] Prompt -> Embeddings
↳ This prompt has never received human feedback directly
↳ [S] is the special start symbol
[11] Transformer
↳ Attention (yellow)
↳ Feed Forward (4x2 weight and bias matrix)
↳ Output: 3 "transformed" feature vector, one per position
↳ More details in my previous post 8. Transformer [https://lnkd.in/g39jcD7j]
[12] Output Probabilities
↳ Apply a linear layer to map each transformed feature vector to a probability distribution over the vocabulary.
[13] Sample
↳ Apply the greedy method, which is to pick the word with the highest score
↳ For output positions 1 and 2, the model accurately predicts the next word, because the model was trained to do in the pretraining phase.
↳ For 3rd output position, the model's predicts "him"
[14] Reward Model
↳ The new pair (CEO is, him) is fed to the reward model
↳ The process is same as [3]-[6]
↳ Output: Reward = 3
[15] Loss Gradient
↳ We set the loss as the negative of the reward. Then, as the loss is minimized, the reward is maximized, the LLM is more aligned to human preferences.
↳ The loss gradient is simply a constant -1.
↳ Run backpropagation and gradient descent to update LLM's weights and biases (red border)
Download the blank below, print, calculate, learn, and celebrate!