


26. LSTM
Can you calculate this by hand? ✍️

LSTMs have been the most effective architecture to process long sequences of data, until our world was taken over by the Transformers.
LSTMs belong to the broader family of recurrent neural network (RNNs) that process data sequentially in a recurrent manner.
Transformers, on the other hand, abandon recurrence and use self-attention instead to process data concurrently in parallel.
Recently, there is renewed interest in recurrence as people realized self-attention doesn’t scale to extremely long sequences, like hundreds of thousands of tokens. Mamba is a good example to bring back recurrence.
All of a sudden, it is cool to study LSTMs.
How do LSTMs work?
Walkthrough
[1] Given
↳ 🟨 Input sequence X1, X2, X3 (d = 3)
↳ 🟩 Hidden state h (d = 2)
↳ 🟦 Memory C (d = 2)
↳ Weight matrices Wf, Wc, Wi, Wo
Process t = 1
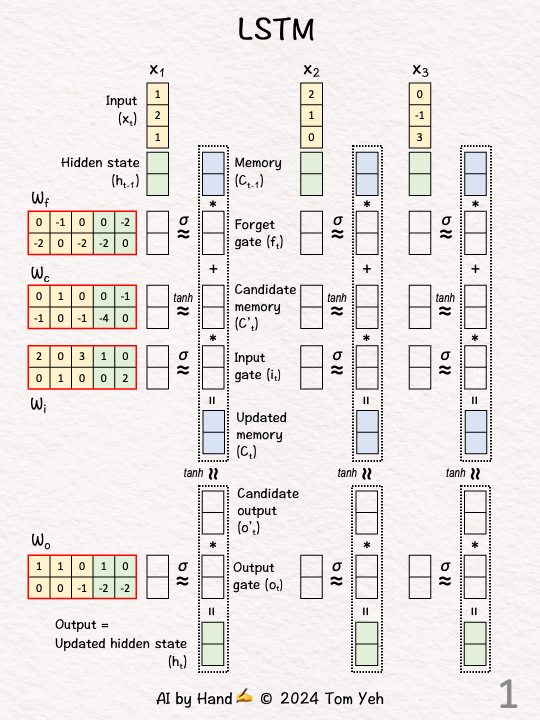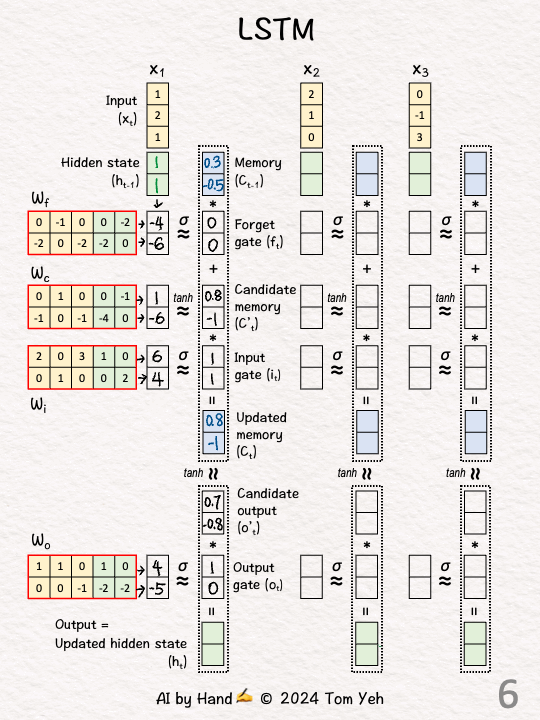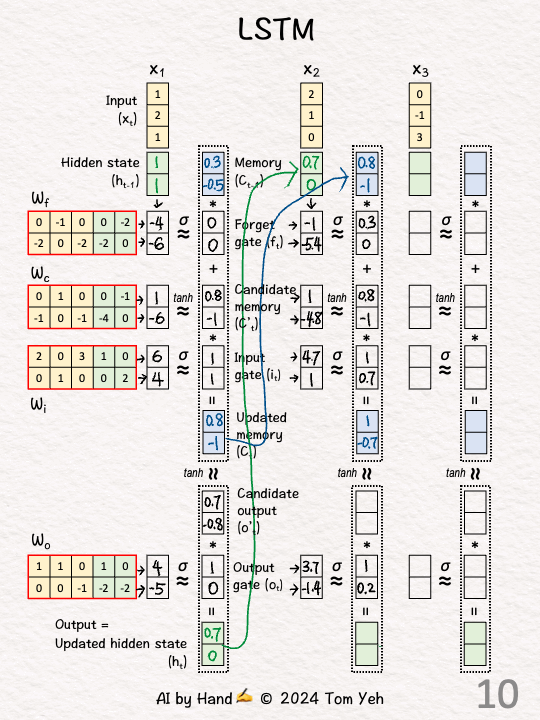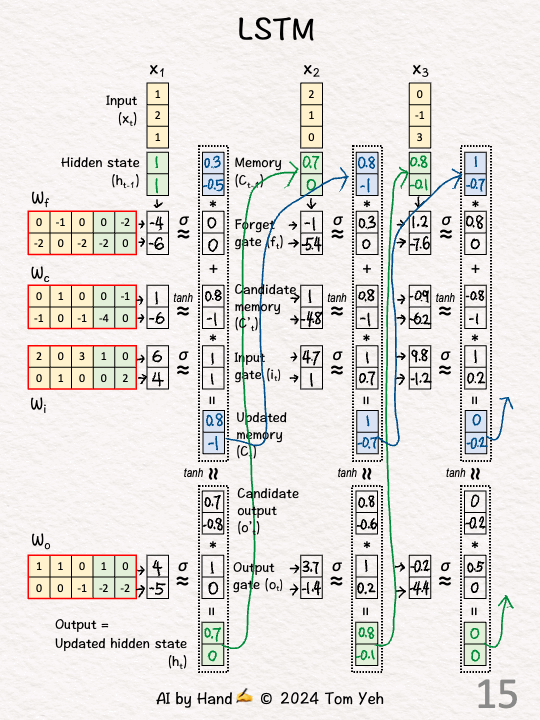
[2] Initialize
↳ Randomly set the previous hidden state h0 to [1, 1] and memory cells C0 to [0.3, -0.5]
[3] Linear Transform
↳ Multiply the four weight matrices with the concatenation of current input (X1) and the previous hidden state (h0).
↳ The results are feature values, each is a linear combination of the current input and hidden state.
[4] Non-linear Transform
↳ Apply sigmoid σ to obtain gate values (between 0 and 1).
Forget gate (f1): [-4, -6] → [0, 0]
Input gate (i1): [6, 4] → [1, 1]
Output gate (o1): [4, -5] → [1, 0]
↳ Apply tanh to obtain candidate memory values (between -1 and 1)
Candidate memory (C’1): [1, -6] → [0.8, -1]
[5] Update Memory
↳ Forget (C0 .* f1): Element-wise multiply the current memory with forget gate values.
↳ Input (C’1 .* o1): Element-wise multiply the “candidate” memory with input gate values.
↳ Update the memory to C1 by adding the two terms above: C0 .* f1 + C’1 .* o1 = C1
[6] Candiate Output
↳ Apply tanh to the new memory C1 to obtain candidate output o’1.
[0.8, -1] → [0.7, -0.8]
[7] Update Hidden State
↳ Output (o’1 .* o1 → h1): Element-wise multiply the candidate output with the output gate.
↳ The result is updated hidden state h1
↳ Also, it is the first output.
Process t = 2
[8] Initialize
↳ Copy previous hidden state h1 and memory C1
[9] Linear Transform
↳ Repeat [3]
[10] Update Memory (C2)
↳ Repeat [4] and [5]
[11] Update Hidden State (h2)
↳ Repeat [6] and [7]
Process t = 3
[12] Initialize
↳ Copy previous hidden state h2 and memory C2
[13] Linear Transform
↳ Repeat [3]
[14] Update Memory (C3)
↳ Repeat [4] and [5]
[15] Update Hidden State (h3)
↳ Repeat [6] and [7]
Download
Hello Sir,
I would like to thank you for the valuable content,
Would you please demonstrate State Space Models by hand!