


8. Transformer
Can you calculate this by hand? ✍️

To study the transformer architecture, it is like opening up the hood of a car and seeing all sorts of engine parts: embeddings, positional encoding, feed-forward network, attention weighting, self-attention, cross-attention, multi-head attention, layer norm, skip connections, softmax, linear, Nx, shifted right, query, key, value, masking. This list of jargons feels overwhelming!
What are the key parts that really make the transformer (🚗) run?
In my opinion, the 🔑 key is the combination of: attention weighting and feed-forward network.
All the other parts are enhancements to make the transformer (🚗) run faster and longer, which is still important because those enhancements are what lead us to "large" language models. 🚗 -> 🚚
Walkthrough
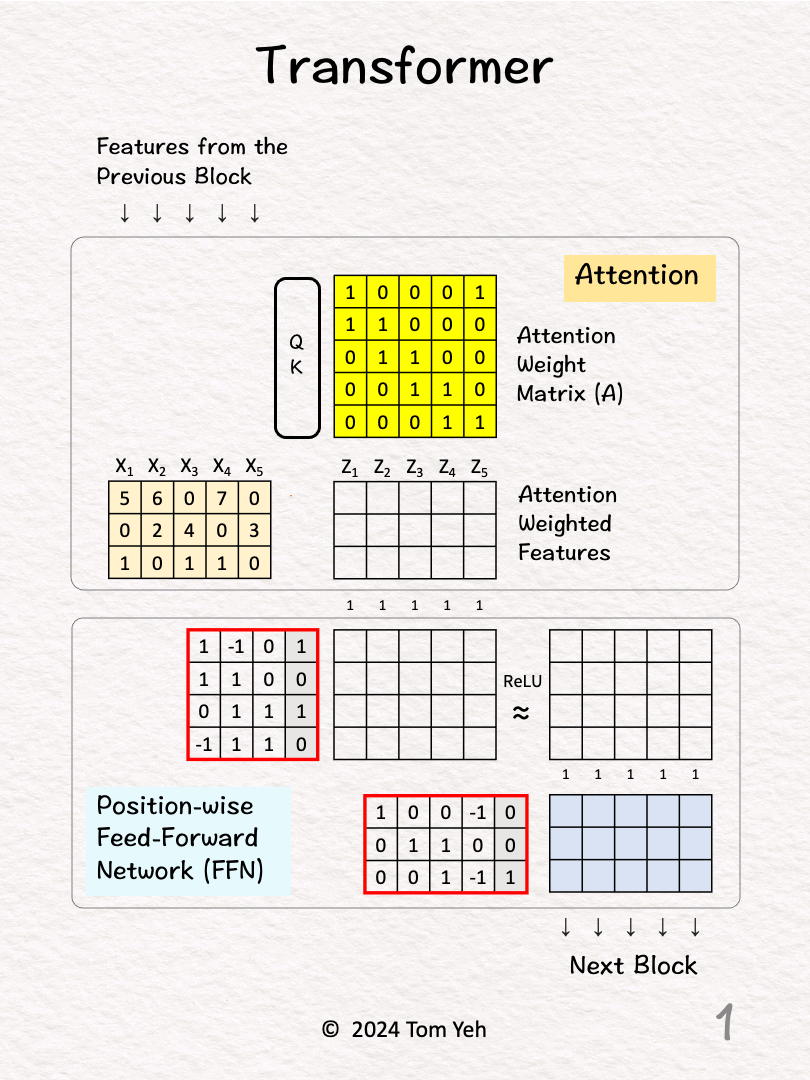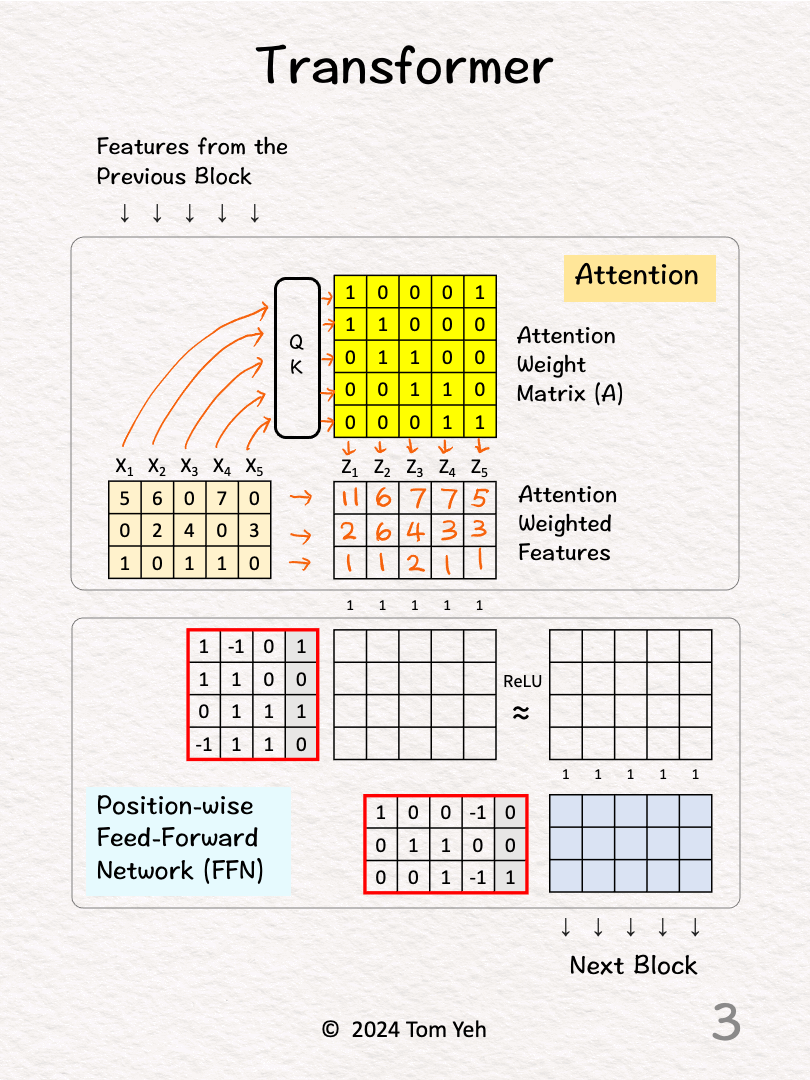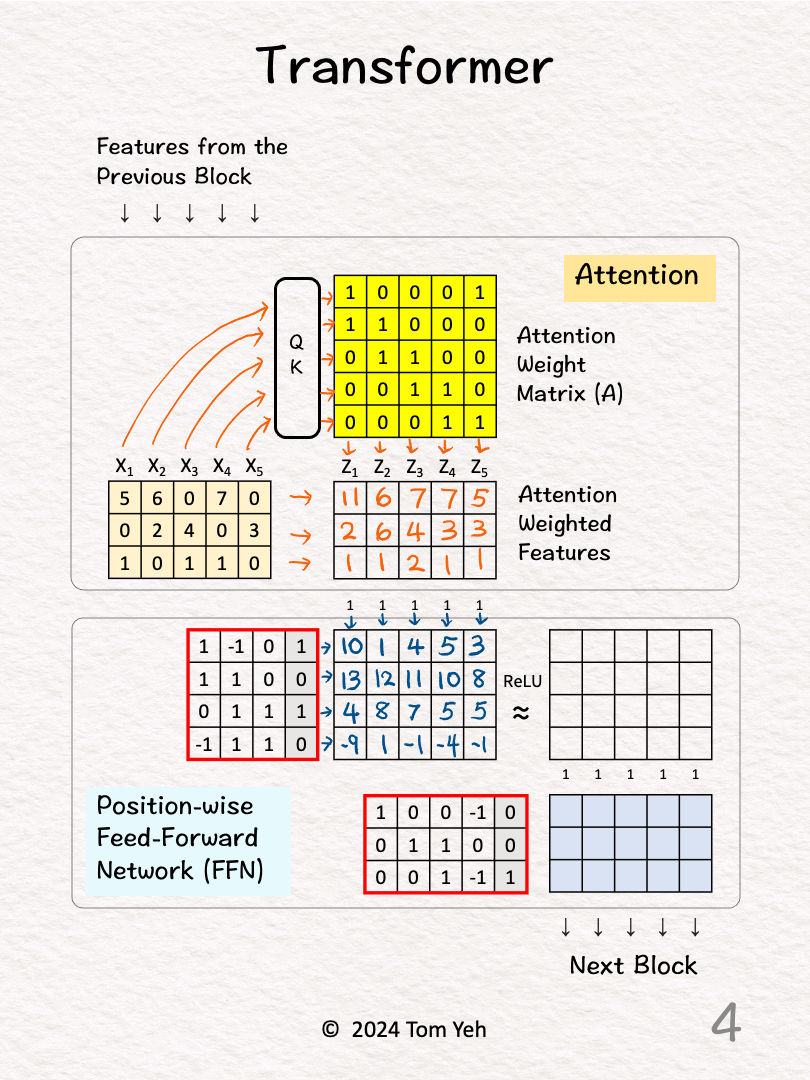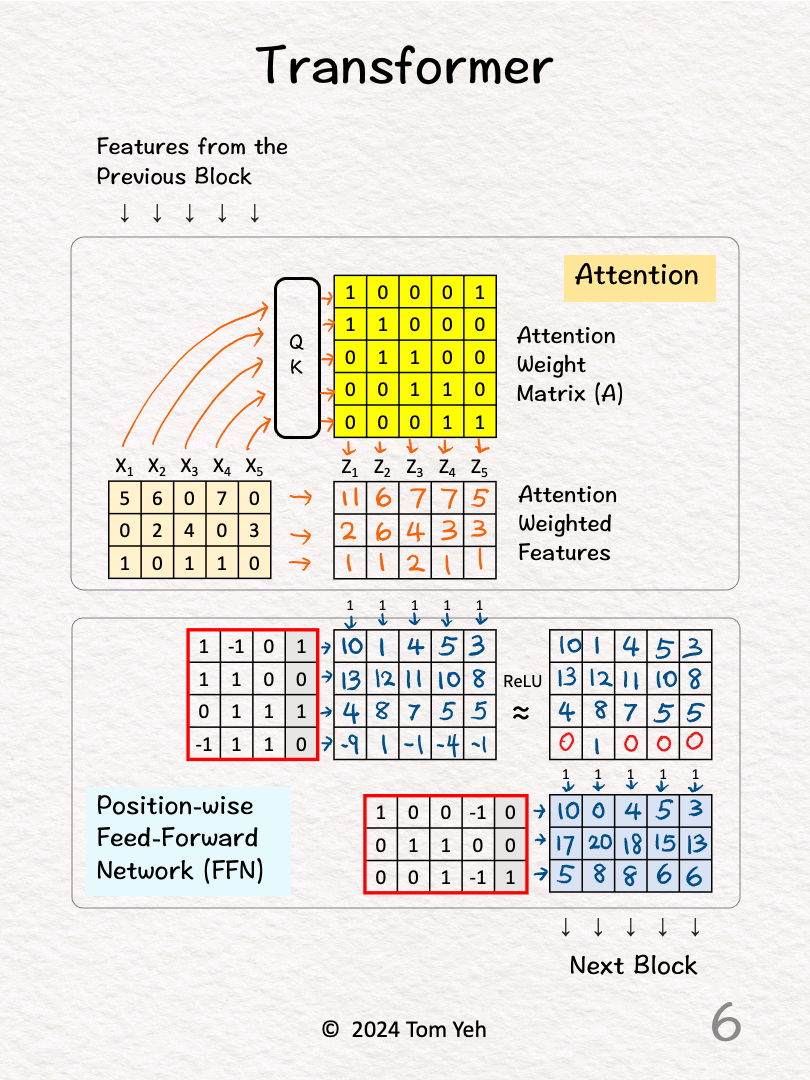
[1] Given
↳ Input features from the previous block (5 positions)
[2] Attention
↳ Feed all 5 features to a query-key attention module (QK) to obtain an attention weight matrix (A). I will skip the details of this module. In a follow-up post I will unpack this module.
[3] Attention Weighting
↳ Multiply the input features with the attention weight matrix to obtain attention weighted features (Z). Note that there are still 5 positions.
↳ The effect is to combine features across positions (horizontally), in this case, X1 := X1 + X2, X2 := X2 + X3....etc.
[4] FFN: First Layer
↳ Feed all 5 attention weighted features into the first layer.
↳ Multiply these features with the weights and biases.
↳ The effect is to combine features across feature dimensions (vertically).
↳ The dimensionality of each feature is increased from 3 to 4.
↳ Note that each position is processed by the same weight matrix. This is what the term "position-wise" is referring to.
↳ Note that the FFN is essentially a multi layer perceptron.
[5] ReLU
↳ Negative values are set to zeros by ReLU.
[6] FFN: Second Layer
↳ Feed all 5 features (d=3) into the second layer.
↳ The dimensionality of each feature is decreased from 4 back to 3.
↳ The output is fed to the next block to repeat this process.
↳ Note that the next block would have a completely separate set of parameters.
Together, the two key parts: attention and FFN, transform features both across positions and across feature dimensions. This is what makes the transformer (🚗) run!