


"Full-Stack" Transformer
Advanced Deep Learning Architectures in Excel

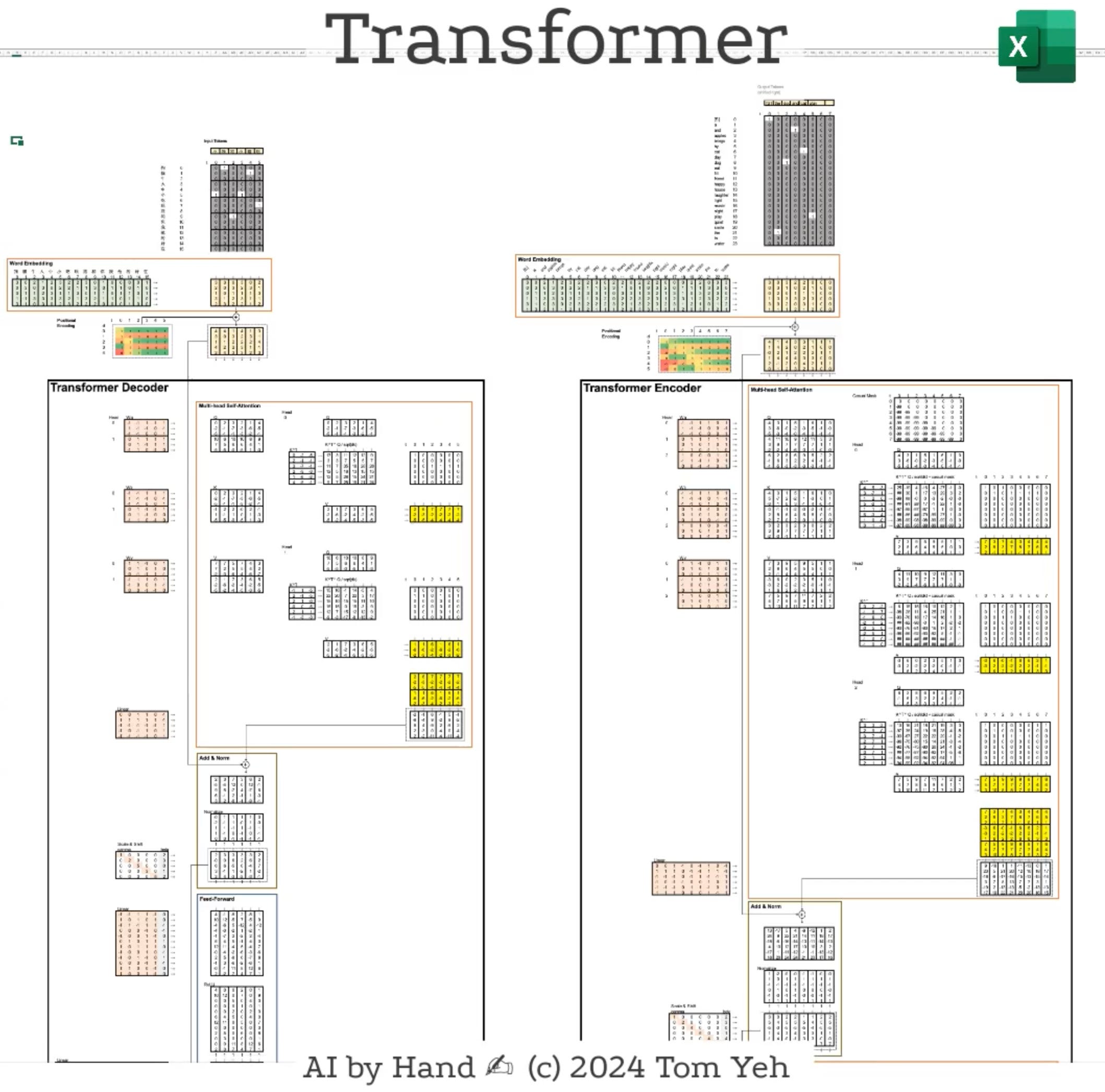
I would like to share with you my "full-stack" Excel implementation of the famous Transformer architecture, brining together all the following components:
Input Embeddings
Output Embeddings
Decoder
Encoder
Positional Encoding
Self-Attention
Cross-Attention
Multi-head Attention
Casual Masking
Scaled Dot Product
Skip Connection
LayerNorm
ReLU Activation
Feed Forward
Softmax
Output Probabilities
Demo Video
Download
Very informative