


OpenAI Strawberry 🍓
AI Paper Takeaway by Hand ✍️

How does OpenAI train the Strawberry🍓 (o1) model to spend more time thinking?
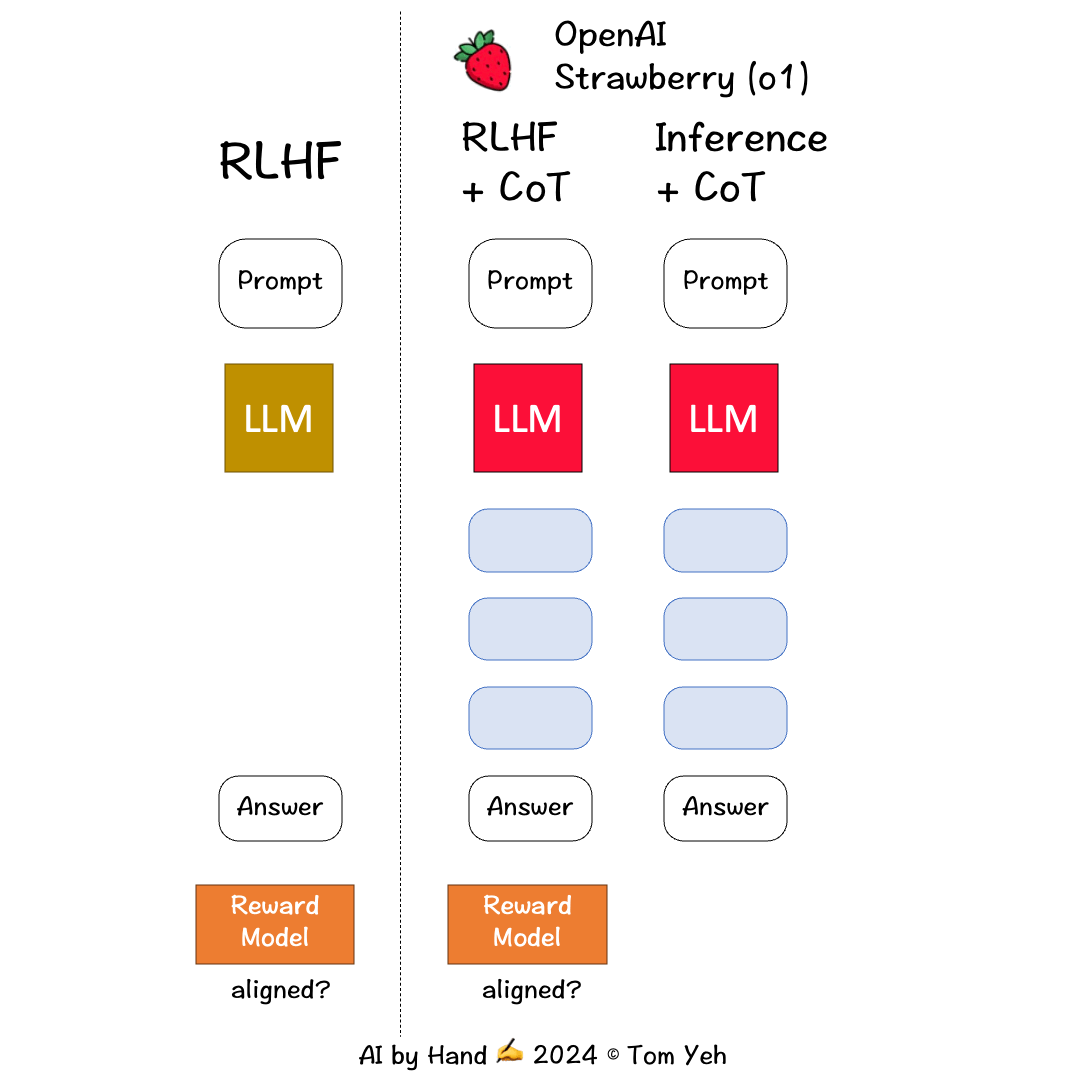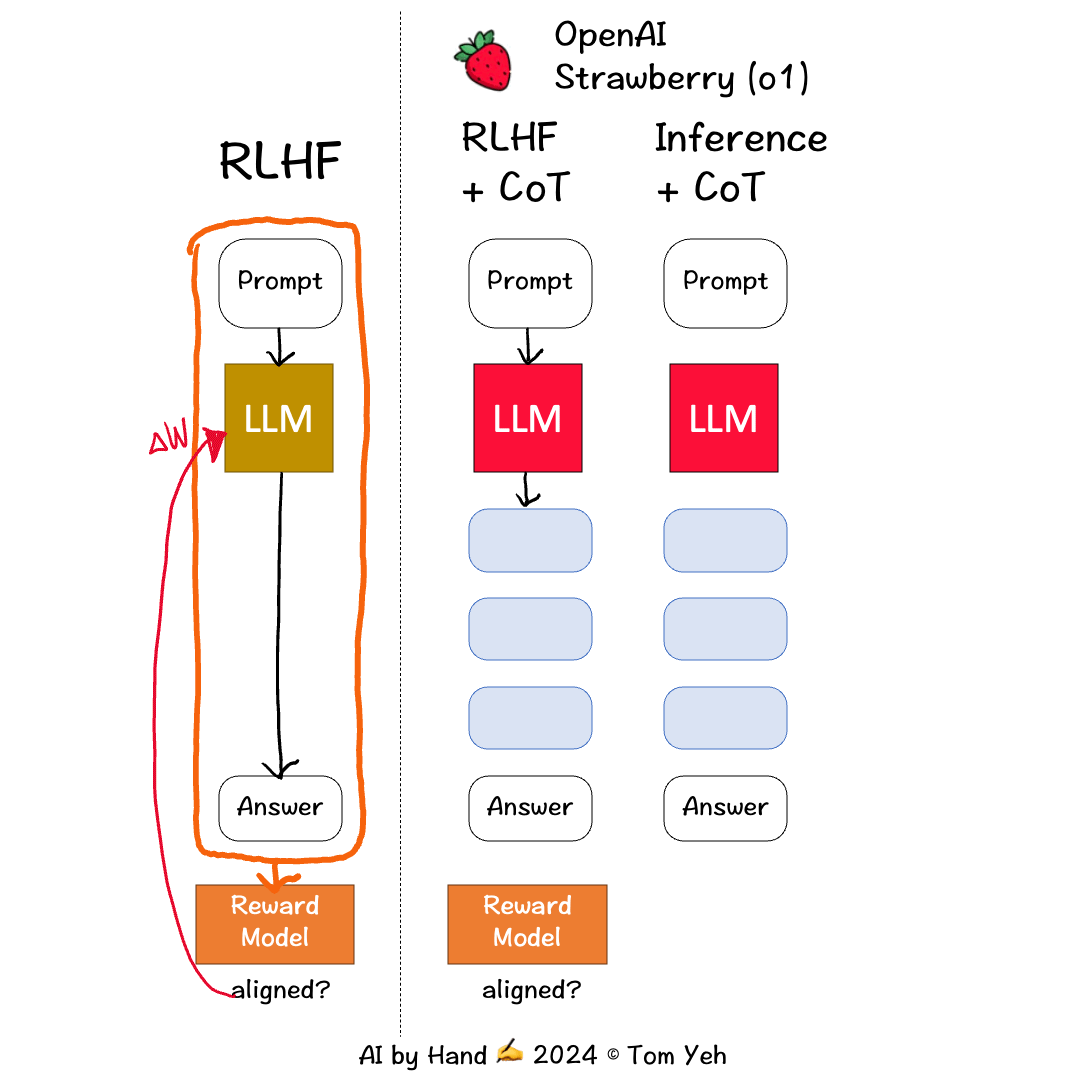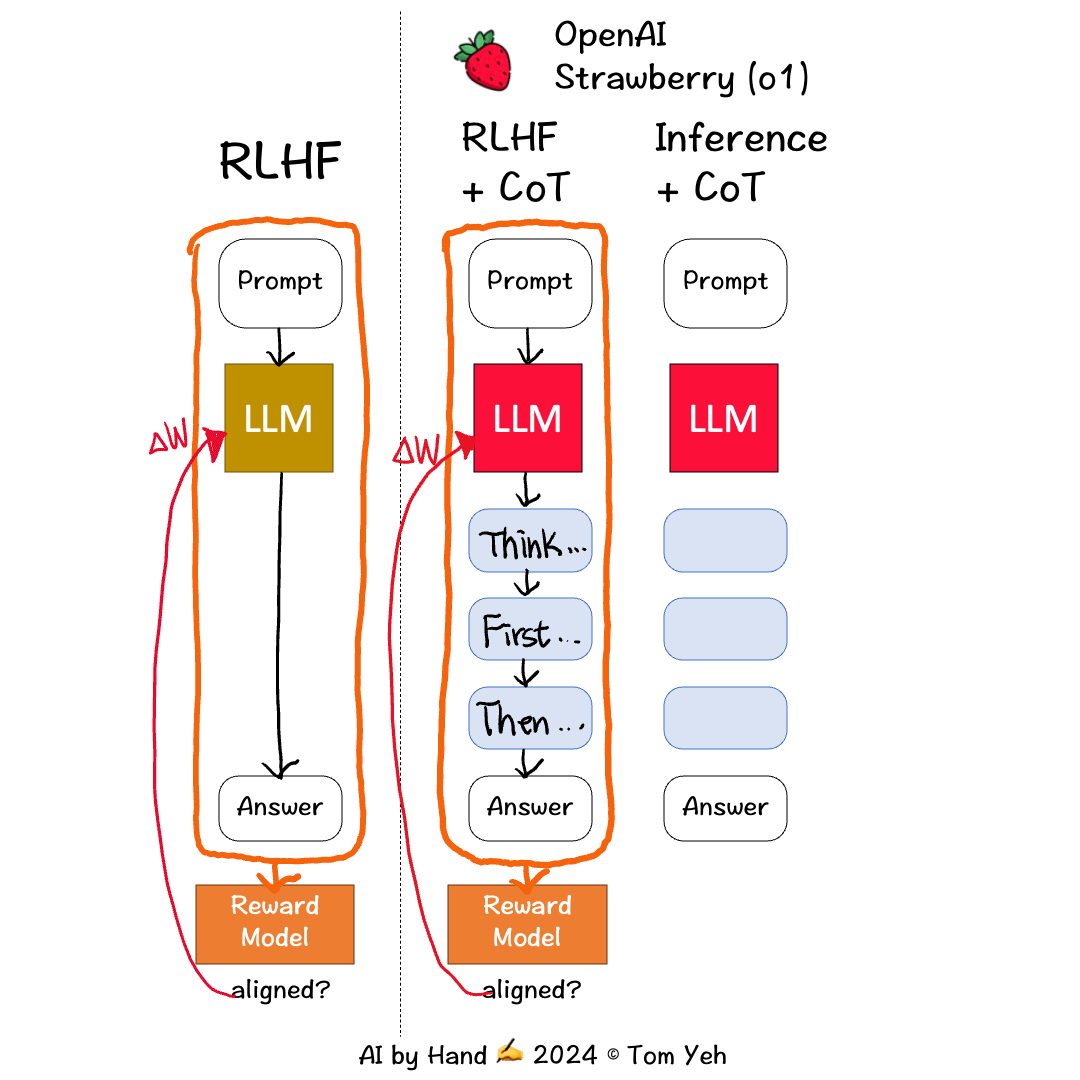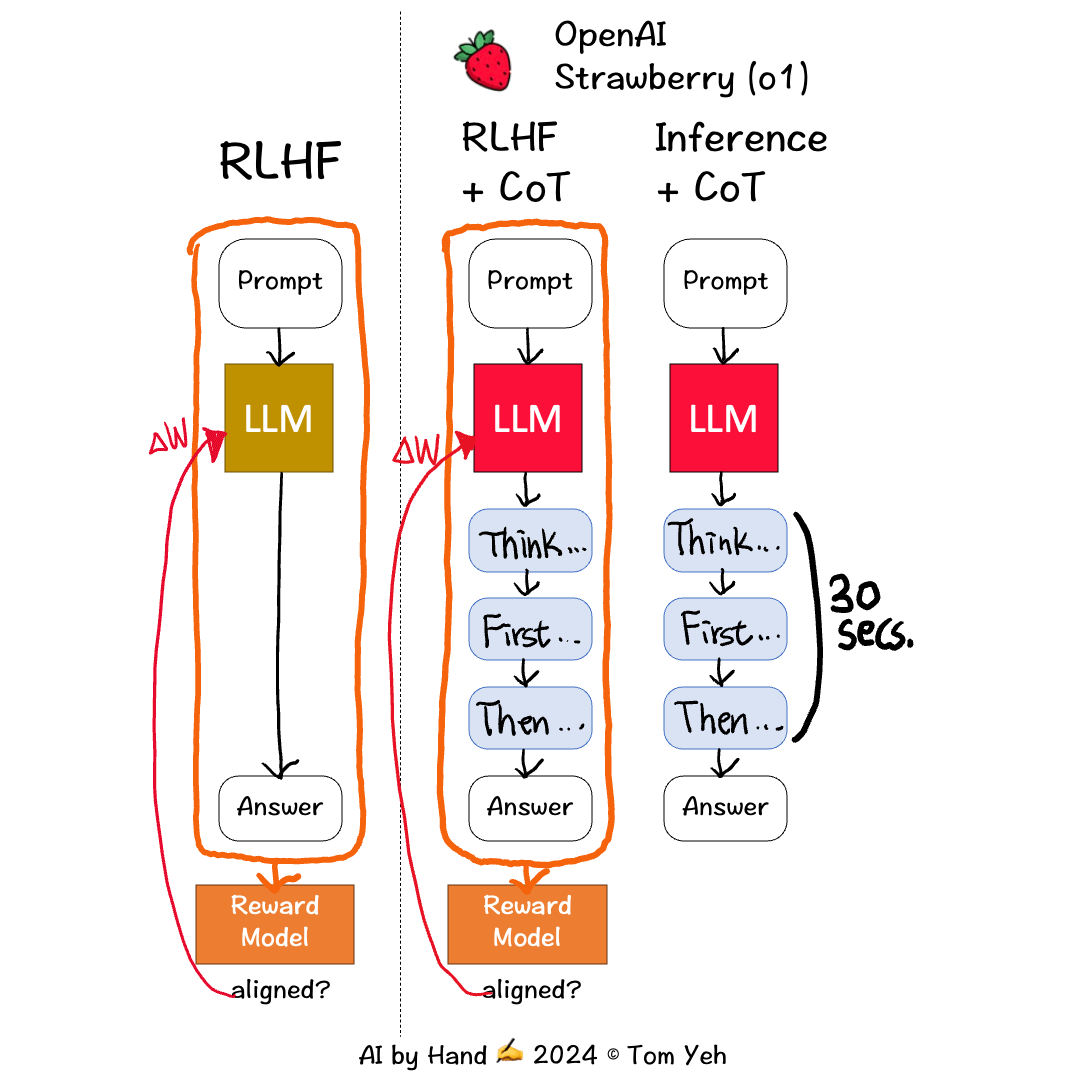
I read OpenAI’s report about their new model. I drew this animation to share my best understanding with you. Their report is mostly about what impressive benchmark results they got. But in term of the how, the report only offers one sentence:
Through reinforcement learning, o1 learns to hone its chain of thought and refine the strategies it uses.
The two key phrases in this sentence are: Reinforcement Learning (RL) and Chain of Thought (CoT).
Among the contributors listed in the report, two individuals stood out to me:
Ilya Sutskever, the (former) leader of OpenAI’s alignment team. He left OpenAI and just started a new company, Safe Superintelligence. Listing Ilya tells me that RLHF still plays a role in training the Strawberry model.
Jason Wei, the author of the famous Chain of Thought paper. He left Google Brain to join OpenAI last year. Listing Jason tells me that CoT is now a big part of RLHF alignment process.
Here are the points I hope to get across in my animation:
💡In RLHF+CoT, the CoT tokens are also fed to the reward model to get a score to update the LLM for better alignment, whereas in the traditional RLHF, only the prompt and response are fed to the reward model to align the LLM.
💡At the inference time, the model has learned to always start by generating CoT tokens, which can take up to 30 seconds, before starting to generate the final response. That's how the model is spending more time to think!
There are other important technical details missing, like how the reward model was trained, how human preferences for the "thinking process" were elicited...etc.
Finally, as a disclaimar, this animation represents my best educated guess. I can't verify the accuracy. I do wish someone from OpenAI can jump out to correct me. Because if they do, we will all learn something useful! 🙌
Thanks for the enlightenment!